
Tencent officially launched its Hunyuan T1 inference model on March 21, 2025, marking a significant advancement in AI reasoning capabilities. This release follows the success of its predecessor, the Hunyuan Turbo S model, which climbed to 15th place on the Chatbot Arena LLM Leaderboard in March 2025. The T1 model is positioned as a competitor to leading models like DeepSeek’s R1 and OpenAI’s o1, emphasizing speed, cost efficiency, and hybrid architecture innovations.
Technical Architecture and Innovations
Hybrid Transformer-Mamba MoE Architecture:
T1 combines Google’s Transformer and Carnegie Mellon/Princeton’s Mamba architectures. This hybrid design reduces training and inference costs by optimizing memory usage while maintaining performance.
Mamba Optimization: Enhances long-sequence processing, enabling faster decoding (2x speed under similar deployment) and improved long-context reasoning.
Mixture-of-Experts (MoE): The model uses 52B active parameters (389B total), making it the largest open-source Transformer-based MoE model.
Reinforcement Learning Focus:
Tencent allocated 96.7% of computing power to reinforcement learning during post-training, prioritizing reasoning ability and alignment with human preferences. Techniques included curriculum learning, data replay, and self-rewarding feedback mechanisms.
Efficiency Enhancements:
- KV Cache Compression: Utilizes Grouped Query Attention (GQA) and Cross-Layer Attention (CLA) to reduce memory overhead.
- Long-Context Support: Pretrained models handle up to 256K tokens, while instruction-tuned versions manage 128K tokens.
Performance and Benchmarks
Reasoning and Knowledge:
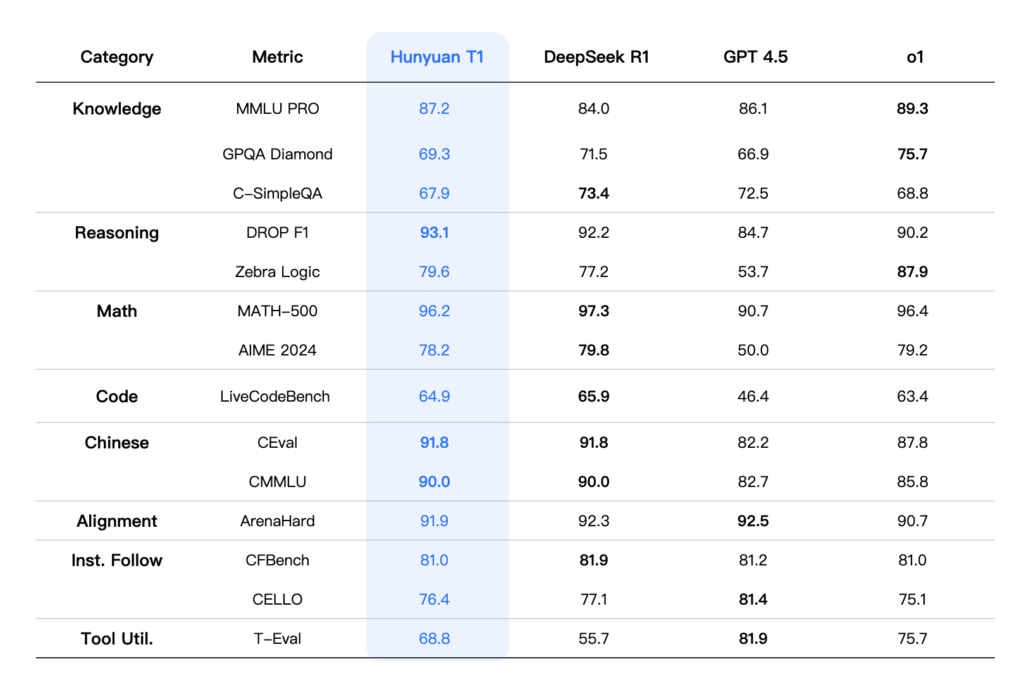
- MMLU-Pro: Scored 87.2 (vs. DeepSeek R1’s 84 and OpenAI o1’s 89.3).
- C-Eval (Chinese): Achieved 91.8, matching R1 and surpassing o1 (87.8).
- AIME 2024: Scored 78.2 (vs. R1’s 79.8 and o1’s 79.2).
Mathematical and Coding Proficiency:
- MATH-500: 96.2, trailing R1 slightly.
- LiveCodeBench: 64.9, demonstrating strong coding capability.
Human Evaluation: Outperforms R1 in cultural creativity, summarization, and agent tasks.
Pricing and Market Positioning
Cost Efficiency:
- Input: 1 yuan (≈$0.14) per million tokens.
- Output: 4 yuan per million tokens, aligning with DeepSeek R1’s off-peak rates.
Competitive Edge: Targets cost-sensitive enterprises while rivaling premium models like o1 in performance.
Applications and Future Directions
Enterprise Use: Integrated with Tencent Cloud’s MaaS (Model-as-a-Service) for industry-specific applications.
Open-Source Availability: The Hunyuan series (including text-to-image and MoE models) is open-sourced on platforms like Hugging Face, fostering community-driven innovation.
Multimodal Expansion: Earlier versions (e.g., May 2024’s DiT-based text-to-image model) highlight Tencent’s focus on multimodal AI, inspired by architectures like OpenAI’s Sora.
Conclusion
Tencent’s Hunyuan T1 represents a significant leap in AI reasoning capabilities, combining cutting-edge hybrid architecture, reinforcement learning, and cost efficiency to challenge global leaders like DeepSeek and OpenAI. Its open-source availability and competitive pricing position it as a versatile tool for enterprises and developers, while its strong performance in Chinese-language tasks and specialized benchmarks highlights its regional and technical strengths. As Tencent continues to innovate in multimodal AI, the Hunyuan series is poised to play a pivotal role in shaping the future of AI applications globally.
Key takeaways
- Hybrid Architecture: T1’s Transformer-Mamba-MoE design reduces costs while enhancing long-context reasoning and speed.
- Benchmark Leadership: Competes closely with DeepSeek R1 and OpenAI o1, excelling in Chinese-language tasks (C-Eval: 91.8) and coding/math benchmarks.
- Reinforcement Learning-Driven: Over 96% of post-training compute focused on RL for reasoning and human preference alignment.
- Cost-Effective Pricing: Aggressive pricing (1 yuan/million tokens input) targets mass adoption, challenging DeepSeek’s affordability.
- Open-Source Ecosystem: Tencent’s Hunyuan series (e.g., 389B-parameter MoE model) is publicly available, encouraging developer collaboration.
- Speed and Scalability: 2x faster decoding than predecessors, with support for 256K-token contexts.
- Multimodal Future: Leverages DiT architecture for text-to-image generation, positioning Hunyuan as a versatile AI suite.
Links
Announcement: https://llm.hunyuan.tencent.com
Hugging Face live demo: Hunyuan-T1
More AI news.

