A new paper challenges the effectiveness of reinforcement learning (RL) in enhancing reasoning abilities of LLMs, suggesting it doesn’t make them smarter.
The study compared two models: a base model (no RL) and a reinforcement learning-enhanced model, with both tested on the same difficult questions.
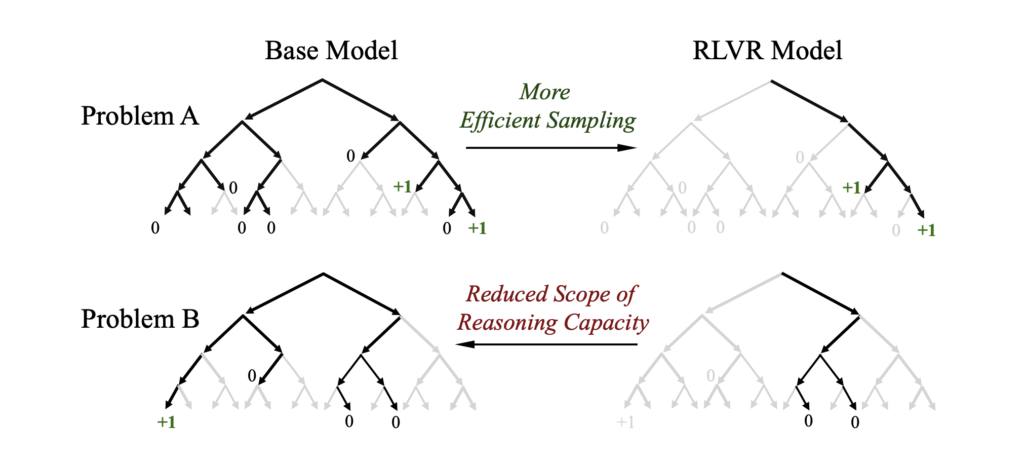
RL helped the enhanced model perform better on the first try but didn’t improve long-term problem-solving ability compared to the base model.
Reinforcement learning accelerates answer retrieval but limits the model’s ability to explore diverse reasoning paths, potentially missing correct answers.
The paper claims RL makes AI more efficient but narrows its scope of reasoning, unlike other methods such as distillation that may help models learn new skills.
The study found that RL doesn’t truly teach new strategies, just makes the AI faster at repeating known solutions, similar to memorization.
Despite faster results, the RL model’s reasoning capacity is limited, as it doesn’t expand the model’s ability to think beyond its initial knowledge.
The research suggests that true progress in AI might require new training paradigms beyond reinforcement learning, as RL doesn’t break through the base model’s cognitive limits.
Links
Document: https://arxiv.org/abs/2504.13837